K-fold Cross Validation for model selection in ML
In the previous post, we’ve learned why we split the dataset into training, validation and testing dataset in terms of machine learning.
If you are not sure about this topic,
check here: Training, Testing and Validation Datasets in Machine Learning
In this post, we will learn:
- What is "K-Fold Cross Validation"
- Why we use this to select the best model.
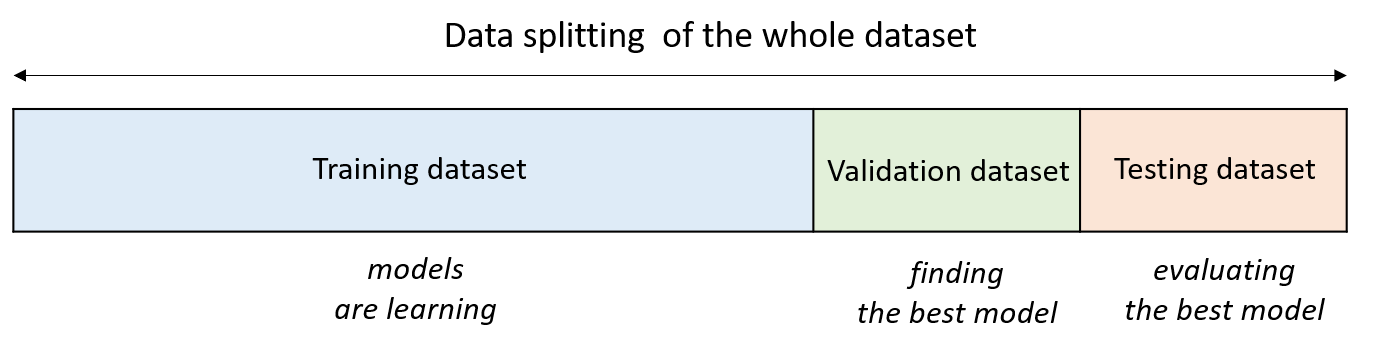
For making a best generalized model, we split the whole dataset into three parts:
- Training dataset (for training a model)
- Validation dataset (for finding a best model)
- Testing dataset (for testing the trained model)
There are two possible problems when splitting the whole dataset into three sets:
- Problem 1: The number of samples for learning can be drastically reduced.
- Problem 2: The randomly chosen training and validation dataset can be not representative enough for all dataset.
SOLUTION:
- We need more training dataset for learning.
- We need use various parts of the training and validation dataset.
For this, we can use cross-validation.
"K-Fold Cross Validation" is one of the cross-validation techniques that we can use.
With this method, the training set is split into subsets by “folding”.
As a result, we are having K number of folds.
Then we are using one fold as a validation dataset to find the best model.
The rest K-1 folds are used for training the models.
Let’s say we are using “5-fold cross-validation” for selecting the best model:
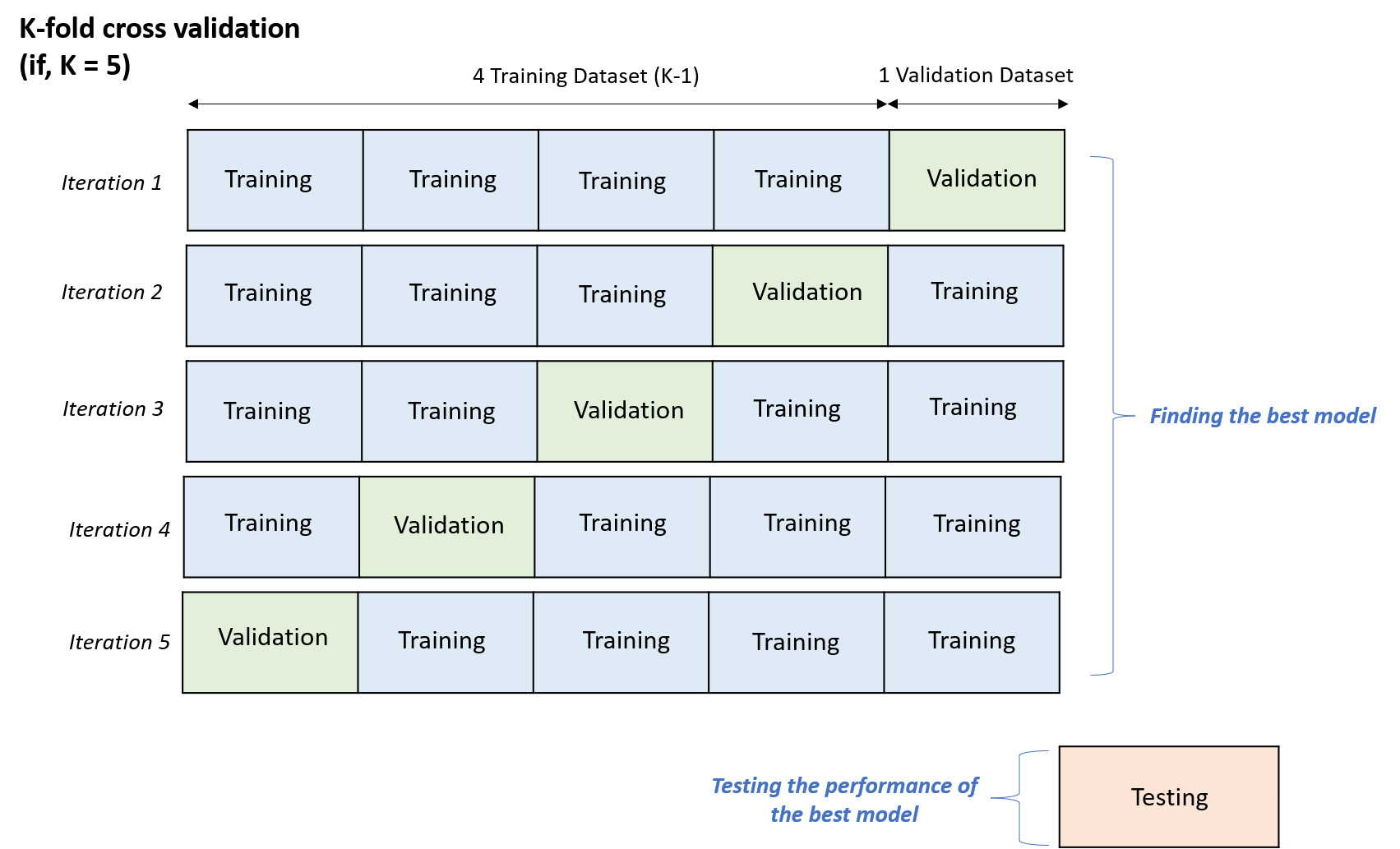
Using cross validation method, we could learn more while iterating 5 times compared to the data splitting method in the first image above.
Furthermore, we could use various parts of the training and validation dataset for learning and validating the performance of the trained model in order to find the best model.
A test dataset is held out for final evaluation of the best model that is chosen by the cross validation.
In the next post, we will learn:
- What is exactly a good model in terms of machine learning.
- What are Overfitting and Underfitting by model validation.
References
- Reference1: 3.1. Cross-validation: evaluating estimator performance
- Reference2: Hold-out Method for Training Machine Learning Models
- Reference3: Model Selection with Cross Validation
- Reference4: Evaluation Methods (hold-out, k-fold, confusion matrix…)(in Korean)
- Reference5: Train, Validation, and Test Set(in Korean)